-
[논문리뷰] End-to-End Object Detection with TransformersResearch/Paper Review 2020. 9. 3. 18:34
1. Introduction
2020년 5월에 face book에서 나온 객체 검출 논문입니다!
객체 검출 task는 객체를 나타내는 bounding box (localization)와 객체의 category label (classification)을 찾는 것입니다.
일반적인 객체 검출 모델들은 이러한 task를 anchor와 같이 간접적인 문제로 수정하여 해결합니다.
이러한 과정은 NMS나 RoI pooling과 같은 비-학습적인 (deep learning스럽지 않은) process를 필요로 합니다.
이 논문은 bipartite matching과 transformer를 이용하여 End-to-End 방식의 OD 구조를 제안합니다.
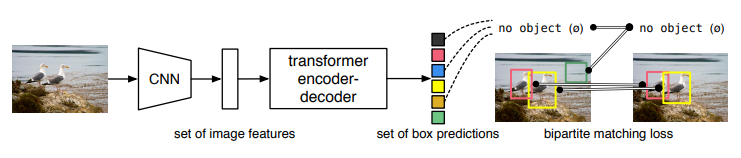
DETR은 parallel하고 direct하게 객체를 검출한다. 전반적인 architecture는 기존의 CNN과 transformer를 조합하여 구성하였다. training 과정에서는 GT에 하나의 prediction이 matching되도록 학습된다. (남는 prediction은 no object class에 종속된다.) 2. Related Work
Set Prediction
하나의 이미지에서 여러 객체를 추정할려고 하다보니, 중복된 객체 추정 결과들이 나오게 됩니다.
기존의 방법들은 NMS(non-maximal suppression) 나 Recurrent model을 사용하여 이러한 문제를 해결하였습니다.
그러나 DETR은 Hungarian algorithm (여러 입력과 출력에 대한 상관성을 추정하는 알고리즘) 기반의 loss를 사용하여 GT와 prediction간의 bipartite matching (이분 매칭; 두 집단을 매칭하는 알고리즘)이 가능하도록 하였습니다.
Transformers
Transformers는 2017년 구글 논문인 'Attention is all you need'에서 발표된 attention machanism 모델입니다.
Transformers는 Sequence data를 처리하는데에 주로 사용되며 attention만으로 계산되기 때문에 기존의 RNN보다 computational은 줄고 성능은 향상되어 NLP, vision, speech, 등 다양한 분야에서 많이 사용됩니다.
3. Proposed Method
Architecture
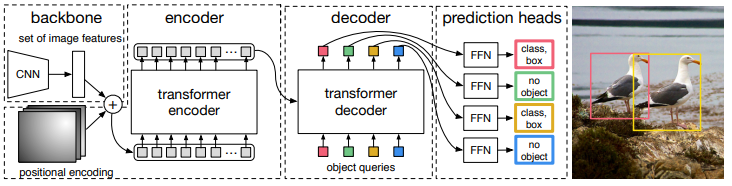
DETR은 CNN으로 2D feature map을 생성하고, 이 feature map을 positional 정보와 함께 transformer에 입력으로 사용, 이후 predicion head단에서 box와 class를 출력한다. 먼저 feature map을 추정하기위해 보편적인 CNN을 사용합니다.
이 논문에서는 주로 resnet-50과 resnet-101을 사용하였습니다.
다음으로는 feature map을 sequence data로 변형과정을 거칩니다. 이 때 1x1 convolution으로 feature map의 channel을 압축하고 feature map의 size (H*W)만큼의 unit을 가진 data가 형성됩니다.
이때 feature map의 spatial domain에 해당하는 부분이 vector화 되기때문에 position에 관한 정보를 잃으며 transformer 구조가 permutation-invariant (순서와 독립된 동일한 출력)이기에 각 unit들에 position 정보를 삽입하는 positional encoding 과정을 거쳐야 합니다.
이후 transformer의 encoder-decoder 구조를 거칩니다.
encoder는 앞선 positional encoded sequence data를 입력받아 attention machanism을 거친 data를 출력합니다.
decoder는 encoder의 출력과 앞선 positional encoding에 해당하는 object queries라고 명명된 embeddings 정보를 입력받아 객체 정보가 담긴 unit들을 출력합니다.
object queries는 입력 영상과 독립된 정보이며 training 과정에서는 학습이 이루어지고 inference 과정에서는 fixed 정보로 사용됩니다.
transformer를 거친 N개의 unit들은 각각 FFN(feed forward networks)를 거쳐 class와 box 정보로 추정됩니다.
이 경우 기존의 OD처럼 영상 내 객체 몇개를 찾는 것이 아닌 무조건적인 N개의 객체를 찾으므로 실제 객체가 아닌 no object 또한 찾도록 학습이 이루어집니다.
transformers

Transformers의 개념에 대해 간략하게 정리하였습니다.
DETR의 Transformer는 attention layers(multi-head self-attention, multi-head attention)과 FFN으로 구성됩니다.
Multi-head self-attention (또는 attention)은 여러 attention layer를 병렬적으로 쌓은 형태이고, FFN(Feed Forward Network)은 일반적인 순방향 신경망이다.
attantion layer는 Scaled dot-product attention으로 Q(query), K(key), V(value)를 입력 받아 그들간의 attention 값을 유추하는 과정입니다.
연산 과정은 Q에 대해 모든 K와 유사도(product)를 구하고 이 유사도를 weight 형태로 K에 해당되는 V에 곱하고 더하는 weighted sum으로 이루어집니다.
Self attention은 query와 key, value가 동일한 경우로 입력된 정보들간의 attention을 구하는 과정을 의미합니다.
Transformer의 encoder는 앞서 설명한 바와 같이 positional encoding된 feature 정보들을 입력받아 muti-head self-attention과 FFN을 거쳐 입력과 동일한 크기의 unit들을 출력합니다.
Decoder는 앞서 설명한 N개의 object queries를 입력받아 multi-head self-attention을 거쳐 가공된 N개의 unit을 출력합니다.
이 N개의 unit들이 query로, 그리고 encoder의 출력 unit들이 Key와 Value로 작동하여 다시한번 multi-head attention을 수행합니다. (Q와 K, V가 다르므로 not self-attention)
이후 FFN을 거쳐 N개의 object queries에 해당하는 N개의 객체 정보가 담긴 unit들을 출력합니다.
최종적으로 이 unit들은 각각 FFN을 거쳐 object class와 box 정보를 출력합니다.
Loss function
DETR은 이미지 내 객체 수 보다 많은 N개의 객체를 출력하도록 구성되어 있습니다.
GT도 prediction과 수를 일치시키기위해서 'no object' 객체로 padding하여 N개의 객체들로 만듭니다.
loss는 이 prediction과 GT를 1대1로 잘 매칭하여 class를 학습하도록, 그리고 매칭된 객체들(no object가 아닌)의 box가 정확하도록 설계되었습니다.
먼저 prdiction과 GT를 1대1로 잘 매칭하기위해 prediction의 순열(순서) $\sigma$를 다음과 같이 찾습니다.

위 식에서 $L_{match}$는 pair-wise matching cost로 두 객체 정보가 잘 matching 되었을 때 낮은 값을 가지도록 다음과 같이 구성됩니다.

p($c_i$)는 class i에 대한 확률이고 $L_{box}$는 box에 대한 loss로 비슷할 수록 낮은 값을 가집니다.
따라서 위 식에서 좌측은 class가 no-object가 아닐 때 해당 class에 대하여 높은 확률을 가질 때 낮은 값을,
그리고 우측식은 객체들의 box가 유사할때 낮은 값을 출력합니다.
즉, no-object가 아닌 객체들에 대해서 GT class에서 높은 확률을, 그리고 GT box와 비슷한 box를 가지는 prediction을 찾기 때문에, GT와 prediction을 잘 matching하는 순열이 됩니다.
그럼 1대1 매칭된 prediction과 GT 사이에서는 다음과 같이 Hungarian 기반의 loss를 사용하여 학습을 진행합니다.

언뜻 보면 $L_{match}$와 비슷하지만 class에 대한 확률 값을 no-object 일 때도 계산한다는 점과 log를 사용하였다는 점이 다릅니다.
이는 matching 순열을 찾을 때는 no-object가 아닌 객체에 대해서만 매칭이 잘 일어나면 되었지만, 학습때는 prediction이 no-object로 가도록 학습이 이뤄져야 되기 때문입니다.
log를 사용한 점은 Box loss와 어느 정도 비율이 비슷해야 한다는 점 (commensurable)을 고려하여 사용하였습니다.
추가적으로 no-object 객체들에 대한 class imbalance 문제를 해결하기 위해 factor 10을 사용하였다고 밝혔습니다.

마지막으로, box loss는 다음과 같이 설계하였습니다.
일반적으로 사용하는 l1-loss는 height과 width와 같은 box의 scale이 클수록 loss가 커집니다
이러한 점을 방지하고자 l1-loss와 scale-invariant한 IoU loss를 같이 사용하여 box loss를 구성하였습니다.
4. Experient Results
사용한 dataset은 COCO 2017 detection을 사용하였고, 학습은 V100 GPU 16개를 사용하여 3일 정도 걸렸다고 밝혔습니다. (short schedule의 경우이고, long schedule은 이보다 약 1.7배 더 오래 학습)
비교 모델은 faster RCNN으로 선정하였고 그 비교 결과 아래 도표와 같습니다.

이외에도 transformer가 attention을 잘하는지, 그리고 각각의 layers에 대한 분석들, loss의 구성에 따른 성능들, DETR로 segmentation task까지 수행한 결과들을 정리해놓았습니다.
5. Conclusion
객체 검출은 딥러닝의 메인 분야 중 하나이고 R-CNN 계열은 그 분야에서도 가장 유명한 알고리즘들이라 첫 리뷰논문으로 DETR을 선정했습니다!
간단하게 정리하려고 했었는데 Transformer라던지 생각보다 길어진 것 같습니다.
그리고 논문 자체에도 학습에 필요한 대부분의 파라미터들과 다양한 실험들, 등 리뷰 글에 다 담지 못할 만큼 많은 내용들이 있어 한번 훑어라도 보시는 것을 추천드립니다! (논문이 26장...)
감사합니다!